Android and background tasks
Android has started to change how background tasks are run. For security and battery life, many new android phones are changing the length of background tasks to terminate within a few seconds of running – killing the desired result. The intention is that apps don’t run things that the user is not aware of in the background.
Imagine apps mining bitcoin in the background!
Possible solutions and options
As mobile technology is not nearly as mature as the web, it can be complicated – even for simple tasks. One would think that if you want to do a task without the user knowing, that you would need a background task – which is not necessarily the case. The operating system (OS) can kill a background service silently if it deems it unnecessary, processing heavy or doesn’t like it. For recurring tasks, this makes the background service a no go.
A foreground service did seem like the next best option. This is a service that runs in the foreground – i.e. there is an icon and a sticky notification that displays. The issue is that pure “handle in the background” tasks are now active and visible.
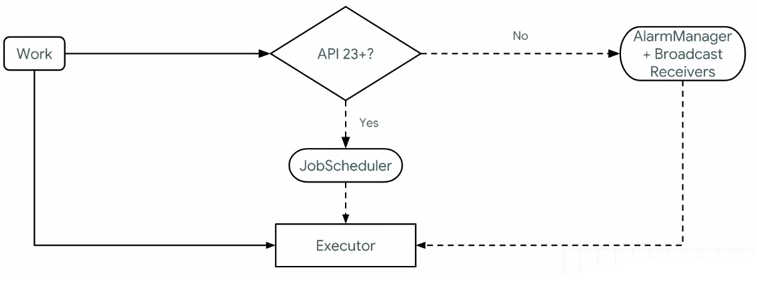
With previous versions of Android, the AlarmManager and Broadcast Receivers work on older devices, whereas API 23+ implemented something called the JobScheduler. This allows us to schedule jobs to be executed. Though you can schedule periodic jobs through the WorkManager, the OS can kill it.
So, using the WorkManager, we can get around this. The WorkManager allows us to create a worker that can run to do a task. Before this completes, we are able to reschedule another event that will allow the worker to execute.
The WorkManager
The Android WorkManager is a library that manages tasks, even if the app exits or the device restarts. It manages this by wrapping the JobScheduler, AlarmManager and BroadcastReceivers all in one. Jon Douglas explains it like this on his Microsoft dev blog:
Permissions
The following permissions are needed to track location:
- ACCESS_FINE_LOCATION – this is for getting the location
- ACCESS_COARSE_LOCATION – this is for getting the location
- ACCESS_BACKGROUND_LOCATION – if you need to access the location in the background, you need this permission for Android 11 (API level 30) or higher.
- FOREGROUND_SERVICE – this will allow the app to run the service.
Technical requirements
For this post, we need to have an Android foreground service and use the WorkManager to handle the scheduling. You can use any of the following libraries:
Architectural code overview
Shared Library / PCL Project calls
We need several things to make this work. The first would be to get something to start the job schedule from the shared library/PCL project:
public interface ILocationWorkerService
{
void StartService();
void StopService();
}
This will be called with dependency resolving as below. Please make sure to register the dependency in the main activity!
DependencyService.Get<ILocationWorkerService>().StartService();
Worker Service
In the Android project, we need an implementation of the interface above, with some place to schedule the worker. I use the name LocationWorkerService, as this is not the worker yet. The Worker is called the LocationWorker.
public class LocationWorkerService : ILocationWorkerService
{
private static Context context = global::Android.App.Application.Context;
public void StartService()
{
OneTimeWorkRequest taxWorkRequest = OneTimeWorkRequest.Builder.From<LocationWorker>()
.SetInitialDelay(TimeSpan.FromSeconds(30)).Build();
WorkManager.Instance.Enqueue(taxWorkRequest);
}
public void StopService()
{
SmarTechMobile.Helpers.Settings.TrackingIsActive = false;
}
}
The Worker
For the worker, we implement the Worker Android-specific class. The code to do the location tracking has been removed here, as links will be supplied further down below.
The code below should run the job repeatedly, every 30 seconds. You might want to add special conditions, such as in the YouShouldResechedule variable – and I recommend doing so, as waking up the device every 30 seconds can be taxing on battery life.
public class LocationWorker : Worker
{
public LocationWorker(Context context, WorkerParameters workerParameters) : base(context, workerParameters)
{
}
public override Result DoWork()
{
try
{
var YouShouldRescedule = true;
if (YouShouldRescedule)
{
Reschedule();
}
}
catch (Exception)
{
Reschedule();
}
return Result.InvokeSuccess();
}
private static void Reschedule()
{
if (SmarTechMobile.Helpers.Settings.TrackingIsActive)
{
OneTimeWorkRequest taxWorkRequest = OneTimeWorkRequest.Builder.From<LocationWorker>()
.SetInitialDelay(TimeSpan.FromSeconds(30)).Build();
WorkManager.Instance.Enqueue(taxWorkRequest);
}
}
}
Location Tracking
There are quite a few libraries that allow for location tracking, and thus it wouldn’t make sense to discuss all of their implementations in detail. I do want to list them with links, so that you can explore them:
The Geolocator plugin was merged into Xamarni Essentials a while back, but it still has some background features that Xamarin Essentials lack. Both are really good though! I use the one by James Montemagno. The location can be called by the following in the worker:
var locator = CrossGeolocator.Current;
var position = await locator.GetLastKnownLocationAsync();
Please make sure that you have all the permissions sorted – anything that happens in the background will fail silently if no permissions were granted.
Conclusion
Location tracking can be complicated. Be careful though – it is recommended that you don’t use it because it’s a nifty feature – the Play store might decline your app if you don’t have a purpose for it. As stated on the documentation:
Note:The Google Play store has updated its policy concerning device location, restricting background location access to apps that need it for their core functionality and meet related policy requirements. Adopting these best practices doesn’t guarantee Google Play approves your app’s usage of location in the background.
The message is this: use functionality with care.
Enjoy your business!